
Cool links behave like links
Please just let me save files
Please just let me save files

People really need to stop blindly copying code from the Internet.
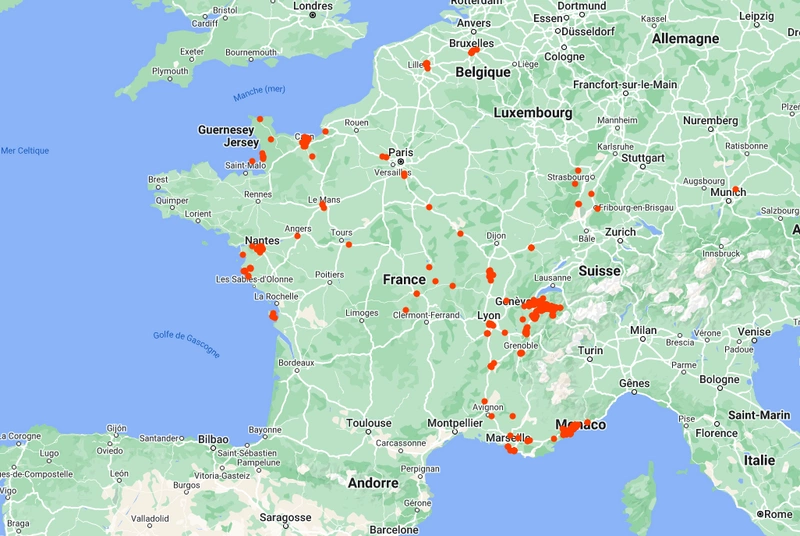
Getting my location history from Google and analyzing it with Python.

Electricity prices have been steadily rising in France for the past few years, with a particularly sharp increase since the beginning of the Russian invasion of Ukraine. This has led me to wonder a...

This is the Burroughs C3155: It’s a charming old 1970s calculator rocking a VFD display and an ostensibly 1970s design. It’s also known, maybe more widely, as the Sharp QT-8D, of which it is a c...
-800.webp)
I recently came into possession of an Olivetti M24, a PC-compatible computer from the 80s. It’s a pretty cool machine from the time, featuring the venerable Intel 8086 CPU, a hard drive of unknown ...
A story of how Microsoft ported Java to .NET and accidentally created Windows Forms in the process, only to throw it away and pretend it never happened.
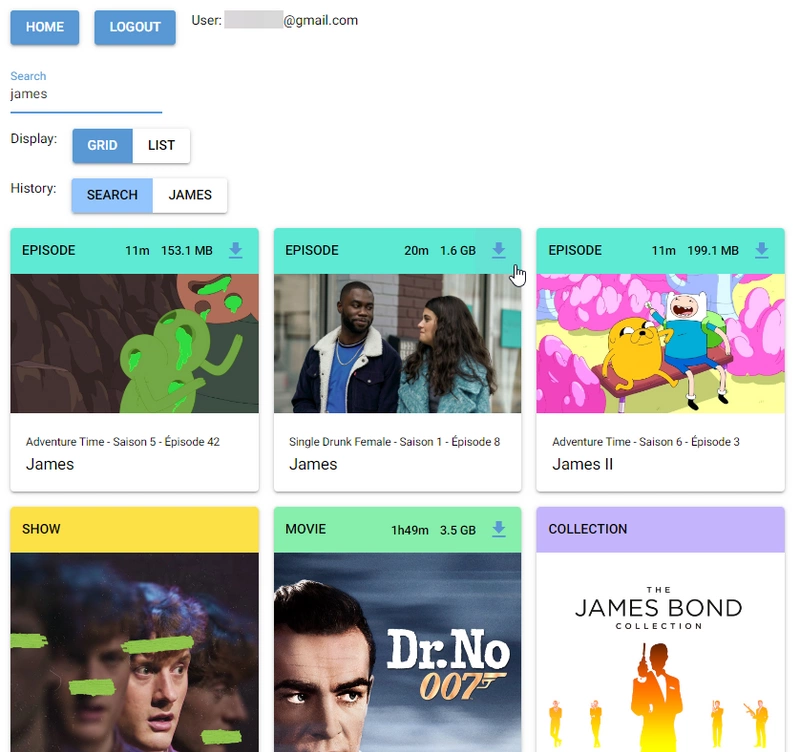
I like Plex I use Plex to share my media with my friends and family. If you don’t know Plex, it’s a nifty tool that basically allows you to take a folder containing movies and TV shows, and share ...

I own a Logitech Z506 5.1 audio system. I bought it in 2014 and it’s been doing its job just fine since then. It looks like this: Audio is easy. It’s just an analog signal you transmit over a wi...

What a time to be alive. GNU/NT is not a fever dream anymore, people actually play games on Linux, and—famously—the Windows ABI is actually the only stable ABI for Linux. Really, it’s something to ...