GPT: Straight Outta Copilot
Ramblings about Copilot, security vulnerabilities, and the originality of ML-generated content.
I’m not a lawyer.
You may have heard about this thing called GitHub Copilot. It’s a tool that can be integrated inside an IDE and allows you to rip off code from licensed code hosted on GitHub. It has no intelligence of its own whatsoever, and any code is spits out must have been written as-is by a human developer at some point.
Oh, wait, sorry. That was Copilot writing a blog post from the perspective of someone that doesn’t like it:

There have been lots of good and bad takes on Copilot these last months, since the release of its technical preview in June of 2021 and its general availability in June of 2022 on a subscription basis.
The recurring themes are, mostly:
- Copilot is a copyright violation machine, since its dataset comes from code written by humans (i.e. intellectual property), and code produced by Copilot should constitute a derivative work.
- Copilot is bad for education, because it offers no guarantee of the correctness of the code written. In the hands of beginners, it can give a false illusion of competency.
- Copilot is bad for security, because it’s just making the same security mistakes that were present in the training data.
The latter two are pretty much self-evident: giving beginners a tool that feels smart and looks like it can produce working code (and pretty much does, a lot of the time) will lead to those same beginners writing way more code than they should while not understanding a single line of it.
Copilot and mistakes
The same way, Copilot was trained on human-written code, including vulnerabilities, so it’s not surprising it would produce the same kinds of vulnerabilities on the code it generates. This can be mitigated, though: in a PHP file containing calls to deprecated mysql_ functions, Copilot will produce code using those same functions and often containing vulnerabilities, but in well-written code, Copilot tends to produce well-written code as well. It’s a completion tool, after all. If you make mistakes, it’ll produce the same mistakes:
![Yesterday, I go to a party with my friend David. He study english with me at university. One day, [Copilot completion starts now] he invite me to go to a party with him.](/assets/posts/2022-11-07-gpt-straight-outta-copilot/image-1.png)
It’s a completion tool, you can just ask it to correct your mistakes, though:
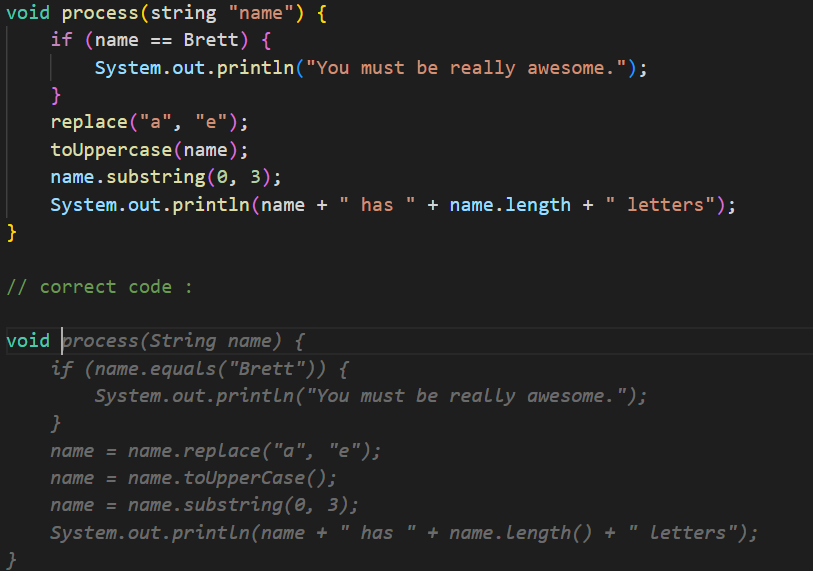
Here is some code that Copilot completed:
1
2
3
4
5
6
7
8
/*<----- Prompt -->*/
$db = mysql_connect("localhost", "root", "root");
mysql_select_db("test", $db);
$username = $_POST['username'];
$password = $_POST['password'];
$query = "SELECT * FROM users WHERE username = '$username' AND password = '$password'"; // SQL injection!
Here’s the same thing, when instead prompted with a PDO call:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/*<- Prompt ->*/
$db = new PDO('mysql:host=localhost;dbname=dbname', 'username', 'password');
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$db->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$db->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC);
$username = $_POST['username'];
$password = $_POST['password'];
$query = "SELECT * FROM users WHERE username = :username AND password = :password";
$stmt = $db->prepare($query);
$stmt->bindParam(':username', $username);
$stmt->bindParam(':password', $password);
$stmt->execute();
Monkey see, monkey do.
It’s a completion tool, it completes bad code with bad code and good code with good code.
Copilot and originality
Some people have been pretty vocal about the originality of code produced by Copilot, specifically asking whether that code is really generated or if it’s simply copied and pasted from the training set. Half an hour of using Copilot is enough, I think, to be convinced that there’s more in Copilot than dumb copy-pasting. Even a StackOverflow lookup, no matter how good the snippet you find, will require you to fix things manually, “fill in” your variable and function names, and so on.
Copilot can generate code that looks original (i.e. that fits in the code around it, does what you ask it to do). Yet, it’s surprisingly easy to make it produce existing code. This is Copilot producing the Fast inverse square root code:
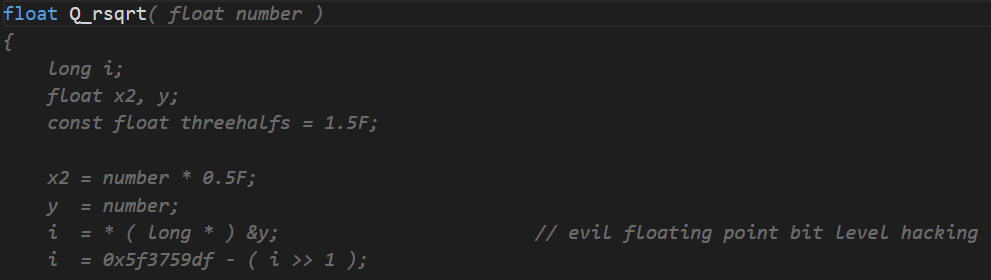
This code is public, but is licensed under the GPLv2 license. However, Copilot didn’t comply with that license, since nowhere in the completion can a GPL attribution notice be found. It’s over, guys, Copilot produces copyrighted code.
This is probably a very good argument for some point, but it’s not a good argument for any side of the “is Copilot-written code original” debate. I think anyone would agree that generally, code written by a human is original, but that doesn’t mean a human can’t plagiarize code. I’ve seen the FISR code so many times in my life, I pretty much know it by heart and could write it if someone asked. However, me writing that bit of code, of existing licensed code, wouldn’t invalidate the originality of all the other code I write.
Now, it’s easy to dismiss the whole thing and just say that Copilot is nothing but a glorified matrix product based on a big list of floats and it’s not like it can even really “understand” something, per se. I know all of this opens the door to philosophical debates like “can an AI learn”, “can an AI understand”, and that’s not what I want to do here. What I can do, is put words on things. When a system takes decisions and these decisions can be influenced by new information given to it, I know no other word to describe this than “learning”. Putting words on things makes reasoning about them easier.
Where’s the line?
Where’s the line, though? Where’s the line between original code and existing code? If I copy someone’s implementation of the Fibonacci sequence, well, I’ve copied it, so either I comply with the license, either it’s plagiarism/copyright violation. But there aren’t that many ways to implement it. For simple enough bits of code, writing original code is going to lead to writing the same code someone else wrote before you.
There’s no direct answer to that: it’s the same thing when a court debates whether a songwriter plagiarized another, a finite number of notes in a finite duration can only lead to a finite number of songs. We’re gonna end up with collisions.
If we ignore obvious cases (copying code directly), when is a different bit of code “the same as” an existing bit of code?
If I take code from a GPL-licensed project written in C and translate it in Python, is it still the same code, under the same license? What if I change the code to make it more idiomatic?
This C code:
1
2
3
4
5
6
7
int sum_squares(size_t len, int *arr) {
int sum = 0;
for (size_t i = 0; i < len; i++) {
sum += arr[i] * arr[i];
}
return sum;
}
Directly translated to Python, would give this:
1
2
3
4
5
6
7
8
9
def sum_squares(len, arr):
sum = 0
i = 0
# no iterators in C, so this is the closest we have
# since we want a *direct* translation
while i < len:
sum += arr[i] * arr[i]
i += 1
return sum
But it’s not idiomatic! You’re gonna replace that while loop with a for iterator loop, with a range() call instead of a counter variable, and the len parameter isn’t useful anymore since arrays are a first-class type in Python and can provide their own length. So we get this:
1
2
3
4
5
def sum_squares(arr):
sum = 0
for i in arr:
sum += i * i
return sum
We’re down one parameter, and we’re not even using the same loop structure. And obviously, since it’s Python, you’re likely to find the more compact and (generally) more readable functional programming way:
1
2
def sum_squares(arr):
return sum(i * i for i in arr)
It’s the same algorithm as the initial code, but where exactly did the transition happen? That’s basically the code version of the Ship of Theseus.
It’s quite easy to observe that Copilot knows how to rearrange code, refactor things, inline/extract variables, change the structures it’s using, so even if you’re starting from a specific algorithm with lots of conditions and stuff like that, you can end up with a bit of code that does not in the least look like the original one.
Parting words
There’s a question to be asked about the legal aspects of training an ML model on licensed code, and that’s an answer I don’t have for you (again: I’m not a lawyer). But the fact that Copilot can and does generate original code can’t be refuted anymore, and people arguing the opposite simply must have never used Copilot in their life, or have asked Copilot to generate entire files, where it’s way easier to get it to produce existing code.
Since I don’t really know how to end this blog post, here are a few examples taken from my “Copilot best-of” folder: